FiftyOne¶
We have collaborated with the team at Voxel51 to integrate their tool, FiftyOne, into Lightning Flash.
FiftyOne is an open-source tool for building high-quality datasets and computer vision models. The FiftyOne API and App enable you to visualize datasets and interpret models faster and more effectively.
This integration allows you to view predictions generated by your tasks in the FiftyOne App, as well as easily incorporate FiftyOne Datasets into your tasks. All image and video tasks are supported!
Installation¶
In order to utilize this integration, you will need to install FiftyOne:
pip install fiftyone
Visualizing Flash predictions¶
This section shows you how to augment your existing Lightning Flash workflows with a couple of lines of code that let you visualize predictions in FiftyOne. You can visualize predictions for classification, object detection, and semantic segmentation tasks. Doing so is as easy as updating your model to use one of the following outputs:
The visualize() function then lets you visualize
your predictions in the
FiftyOne App. This function accepts a list of
dictionaries containing FiftyOne Label objects
and filepaths, which is exactly the output of the FiftyOne outputs when the
return_filepath=True option is specified.
import flash
import torch
from flash.core.data.utils import download_data
from flash.core.integrations.fiftyone import visualize
from flash.image import ImageClassificationData, ImageClassifier
# 1 Download data
download_data("https://pl-flash-data.s3.amazonaws.com/hymenoptera_data.zip")
# 2 Load data
datamodule = ImageClassificationData.from_folders(
train_folder="data/hymenoptera_data/train/",
val_folder="data/hymenoptera_data/val/",
test_folder="data/hymenoptera_data/test/",
predict_folder="data/hymenoptera_data/predict/",
batch_size=16,
)
# 3 Fine tune a model
model = ImageClassifier(
backbone="resnet18",
labels=datamodule.labels,
)
trainer = flash.Trainer(
max_epochs=1,
gpus=torch.cuda.device_count(),
fast_dev_run=True,
)
trainer.finetune(
model,
datamodule=datamodule,
strategy=("freeze_unfreeze", 1),
)
trainer.save_checkpoint("image_classification_model.pt")
# 4 Predict from checkpoint
model = ImageClassifier.load_from_checkpoint("image_classification_model.pt")
predictions = trainer.predict(model, datamodule=datamodule, output="fiftyone") # output FiftyOne format
# 5 Visualize predictions in FiftyOne App
# Optional: pass `wait=True` to block execution until App is closed
session = visualize(predictions, wait=True)
The visualize() function can be used in
all of the following environments:
Local Python shell: The App will launch in a new tab in your default web browser
Remote Python shell: Pass the
remote=Trueoption and then follow the instructions printed to your remote shell to open the App in your browser on your local machineJupyter notebook: The App will launch in the output of your current cell
Google Colab: The App will launch in the output of your current cell
Python script: Pass the
wait=Trueoption to block execution of your script until the App is closed
See this page for more information about using the FiftyOne App in different environments.
Using FiftyOne datasets¶
The above workflow is great for visualizing model predictions. However, if you store your data in a FiftyOne Dataset initially, then you can also visualize ground truth annotations. This allows you to perform more complex analysis with views into your data and evaluation of your model results.
The
from_fiftyone()
method allows you to load your FiftyOne datasets directly into a
DataModule to be used for training,
testing, or inference.
from itertools import chain
import fiftyone as fo
import flash
import torch
from flash.core.classification import FiftyOneLabelsOutput
from flash.core.data.utils import download_data
from flash.image import ImageClassificationData, ImageClassifier
# 1 Download data
download_data("https://pl-flash-data.s3.amazonaws.com/hymenoptera_data.zip")
# 2 Load data into FiftyOne
train_dataset = fo.Dataset.from_dir(
dataset_dir="data/hymenoptera_data/train/",
dataset_type=fo.types.ImageClassificationDirectoryTree,
)
val_dataset = fo.Dataset.from_dir(
dataset_dir="data/hymenoptera_data/val/",
dataset_type=fo.types.ImageClassificationDirectoryTree,
)
test_dataset = fo.Dataset.from_dir(
dataset_dir="data/hymenoptera_data/test/",
dataset_type=fo.types.ImageClassificationDirectoryTree,
)
# 3 Load data into Flash
datamodule = ImageClassificationData.from_fiftyone(
train_dataset=train_dataset,
val_dataset=val_dataset,
test_dataset=test_dataset,
batch_size=4,
)
# 4 Fine tune model
model = ImageClassifier(
backbone="resnet18",
labels=datamodule.labels,
)
trainer = flash.Trainer(
max_epochs=1,
gpus=torch.cuda.device_count(),
limit_train_batches=1,
limit_val_batches=1,
)
trainer.finetune(
model,
datamodule=datamodule,
strategy=("freeze_unfreeze", 1),
)
trainer.save_checkpoint("image_classification_model.pt")
# 5 Predict from checkpoint on data with ground truth
model = ImageClassifier.load_from_checkpoint("image_classification_model.pt")
datamodule = ImageClassificationData.from_fiftyone(predict_dataset=test_dataset, batch_size=4)
predictions = trainer.predict(
model, datamodule=datamodule, output=FiftyOneLabelsOutput(model.labels, return_filepath=False)
) # output FiftyOne format
predictions = list(chain.from_iterable(predictions))
# 6 Add predictions to dataset
test_dataset.set_values("predictions", predictions)
# 7 Evaluate your model
results = test_dataset.evaluate_classifications("predictions", gt_field="ground_truth", eval_key="eval")
results.print_report()
plot = results.plot_confusion_matrix()
plot.show()
# 8 Visualize results in the App
session = fo.launch_app(test_dataset)
# Optional: block execution until App is closed
session.wait()
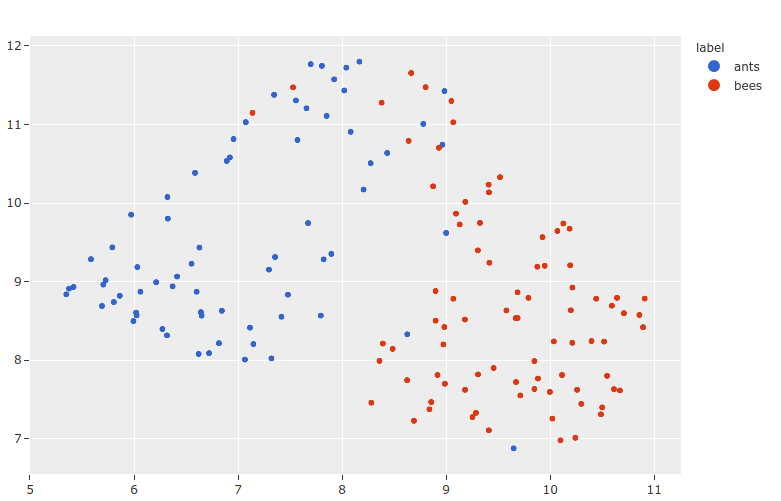
Visualizing embeddings¶
FiftyOne provides the methods for dimensionality reduction and interactive plotting. When combined with embedding tasks in Flash, you can accomplish powerful workflows like clustering, similarity search, pre-annotation, and more in only a few lines of code.
import fiftyone as fo
import fiftyone.brain as fob
import flash
import numpy as np
import torch
from flash.core.data.utils import download_data
from flash.image import ImageEmbedder
from flash.image.classification.data import ImageClassificationData
# 1 Download data
download_data("https://pl-flash-data.s3.amazonaws.com/hymenoptera_data.zip")
# 2 Load data into FiftyOne
dataset = fo.Dataset.from_dir(
"data/hymenoptera_data/test/",
fo.types.ImageClassificationDirectoryTree,
)
datamodule = ImageClassificationData.from_files(
predict_files=dataset.values("filepath"),
batch_size=16,
)
# 3 Load model
embedder = ImageEmbedder(backbone="resnet18")
# 4 Generate embeddings
trainer = flash.Trainer(gpus=torch.cuda.device_count())
embedding_batches = trainer.predict(embedder, datamodule=datamodule)
embeddings = np.stack(sum(embedding_batches, []))
# 5 Visualize in FiftyOne App
results = fob.compute_visualization(dataset, embeddings=embeddings)
session = fo.launch_app(dataset)
plot = results.visualize(labels="ground_truth.label")
plot.show()
# Optional: block execution until App is closed
session.wait()