LARS¶
- class flash.core.optimizers.LARS(params, lr=<required parameter>, momentum=0, dampening=0, weight_decay=0, nesterov=False, trust_coefficient=0.001, eps=1e-08)[source]¶
Extends SGD in PyTorch with LARS scaling.
See the paper Large batch training of Convolutional Networks
- Parameters
params¶ (iterable) – iterable of parameters to optimize or dicts defining parameter groups
weight_decay¶ (float, optional) – weight decay (L2 penalty) (default: 0)
dampening¶ (float, optional) – dampening for momentum (default: 0)
nesterov¶ (bool, optional) – enables Nesterov momentum (default: False)
trust_coefficient¶ (float, optional) – trust coefficient for computing LR (default: 0.001)
eps¶ (float, optional) – eps for division denominator (default: 1e-8)
Example
>>> from torch import nn >>> model = nn.Linear(10, 1) >>> optimizer = LARS(model.parameters(), lr=0.1, momentum=0.9) >>> optimizer.zero_grad() >>> # loss_fn(model(input), target).backward() >>> optimizer.step()
Note
The application of momentum in the SGD part is modified according to the PyTorch standards. LARS scaling fits into the equation in the following fashion.
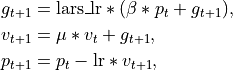
where
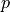 ,
, 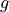 ,
,  ,
, 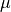 and
and 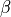 denote the
parameters, gradient, velocity, momentum, and weight decay respectively.
The
denote the
parameters, gradient, velocity, momentum, and weight decay respectively.
The 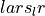 is defined by Eq. 6 in the paper.
The Nesterov version is analogously modified.
is defined by Eq. 6 in the paper.
The Nesterov version is analogously modified.Warning
Parameters with weight decay set to 0 will automatically be excluded from layer-wise LR scaling. This is to ensure consistency with papers like SimCLR and BYOL.
